A Definitive Classification System for Starch-Based Mexican Street Food
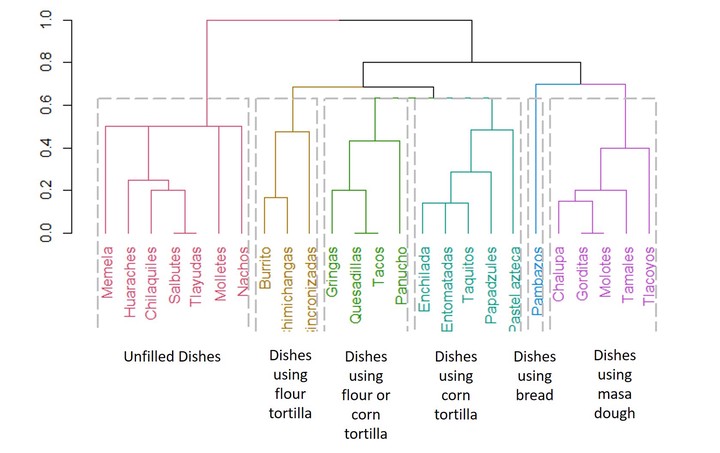 A difinitive classification system for starch-based Mexican street food.
A difinitive classification system for starch-based Mexican street food.
Date
Jan 23, 2020 12:00 AM
Event
Team RHIJ Biweekly Meeting
Context
I really like clustering algorithms; I think they’re under-used in experimental biology. Using k-means clustering was the contribution I was most proud of to the hydrogen–deuterium exchange epitope mapping data analysis workflow David and I worked out in this publication. Often in the literature an arbitrary minimum of exchange is set to count a peptide into the epitope with not much justification; using k-means clustering sets the minumum mathematically based on the data itself and allows the minimum to scale.
However, k-means clustering can only be used on numeric datasets. This project was an excuse to learn more about how to cluster categorical datasets and how to make HTML slides with reveal.js.
Reveal.JS slides are 2-dimensional; right advances through sections and down advances through slides within each section.